Network infrastructure can have implications for EBITDA reporting, cash flow, and valuation. Here’s what CFOs need to know before their next network refresh.
8 min readResources
Replay
MeterUp 2025
WatchWatch the content replays from MeterUp 2025, the annual event for networking.

Report
Meter named a Visionary in the 2026 Gartner® Magic Quadrant™
Download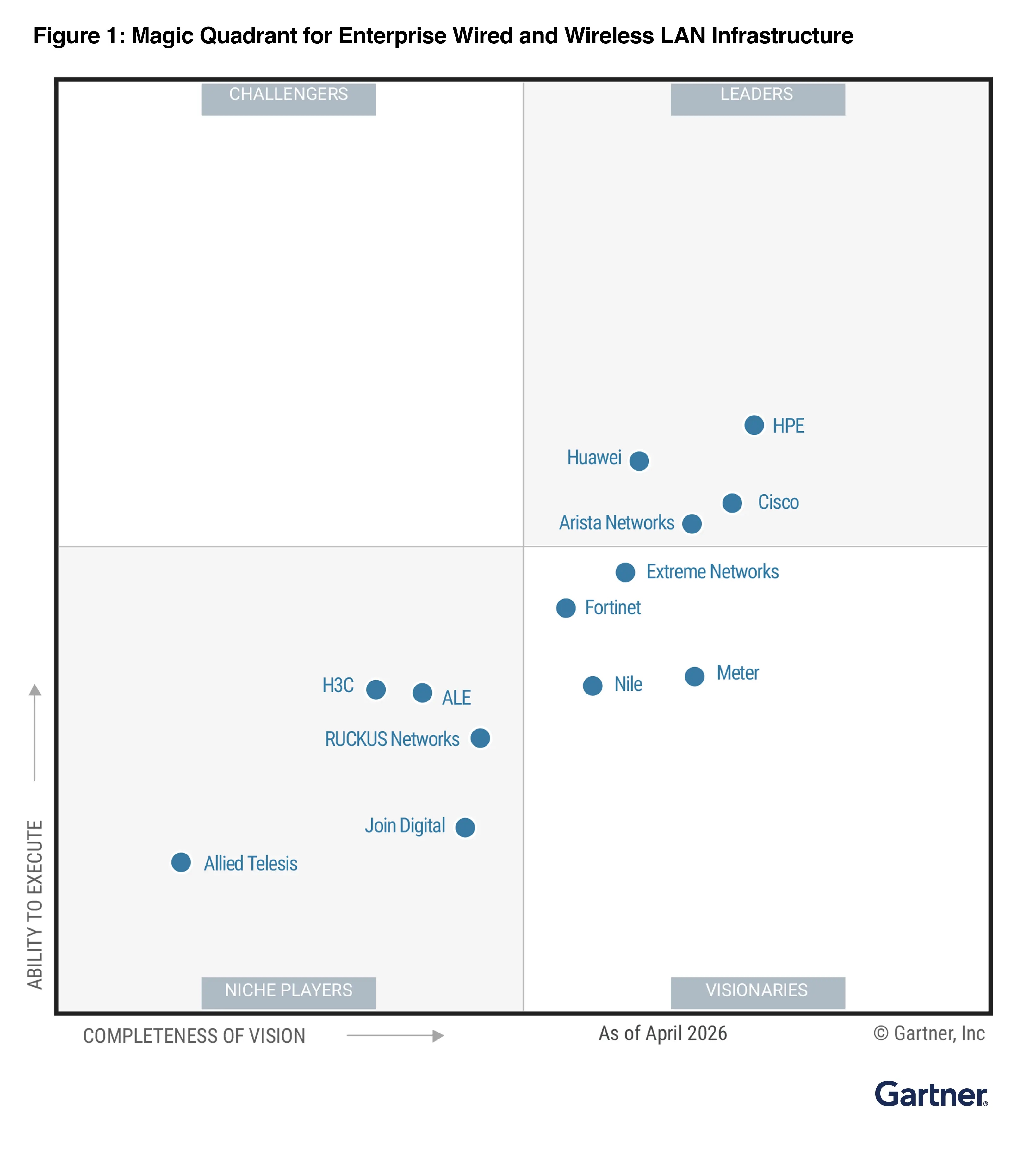
Pricing
Capital lease
ReadMeter’s capital lease option gives you the financial outcomes of CapEx with the benefits of leasing.

Specs
Meter hardware specs

Guide
Guide
A structured way to evaluate indoor cellular. Understanding the requirements, technology approaches, and make informed decisions based on your long-term needs.
DownloadGuide
Use E-Rate funding to upgrade your school's technology infrastructure. Learn how E-Rate supports Internet access, networking hardware, and more.
22 min readGuide
Managed IT services for schools offer tech support, improve security, and reduce costs, allowing staff to focus on education instead of tech issues.
13 min readGuide
Enhance your store with guest access for retail. Discover how offering Wi-Fi to shoppers can increase foot traffic, boost sales, and collect valuable insights.
11 min readGuide
Get insights on network service management, from tools to best practices, and see how it boosts performance, security, and reduces downtime.
16 min readGuide
Common network security pitfalls, how to fix them with first principles, and how Meter does network security.
DownloadGuide
Internet outages can bring warehouse operations to a stand-still. Learn about the 3 key changes modern warehouses are making to prevent internet outages.
DownloadGuide
From navigating vendor pitches to streamlining complex architectures, learn how to design a simple, effective network that prioritizes security without breaking the bank.
DownloadGuide
The trade-offs of each different type of business internet connections and provide recommendations on how to choose the best product for your business.
6 min readGuide
All you need to know about selecting an internet service provider (ISP) — for any business and commercial space.
12 min readGuide
We discuss how Wi-Fi speed is measured, the differences between quoted Wi-Fi performance expectations vs. reality, and how to determine what speed you need.
11 min readReport
Meter has been recognized as a Visionary in the 2026 Gartner® Magic Quadrant™ for Enterprise Wired and Wireless LAN.
Read reportReport
Meter has been recognized as a Visionary in the 2025 Gartner® Magic Quadrant™ for Enterprise Wired and Wireless LAN Infrastructure.
Read reportReport
See why Meter was named IDC Innovator in Enterprise Network as a Service.
Read reportPartners
SwiftWorks breaks down why combining a smarter underlay with intelligent overlays is the key to simpler, more resilient enterprise networks.
DownloadTrusted by technology and networking leaders everywhere
Customer storiesWhen we first started looking into how we could scale across the country, we knew we needed a partner that could help us with networking. Moving across several different states, with different locations, the company was growing quickly and networking as a service was going to be a requirement.
Codi HandleyDirector of Security & IT